To integrate HUAWEI Accelerate Kit, you must complete the following preparations:
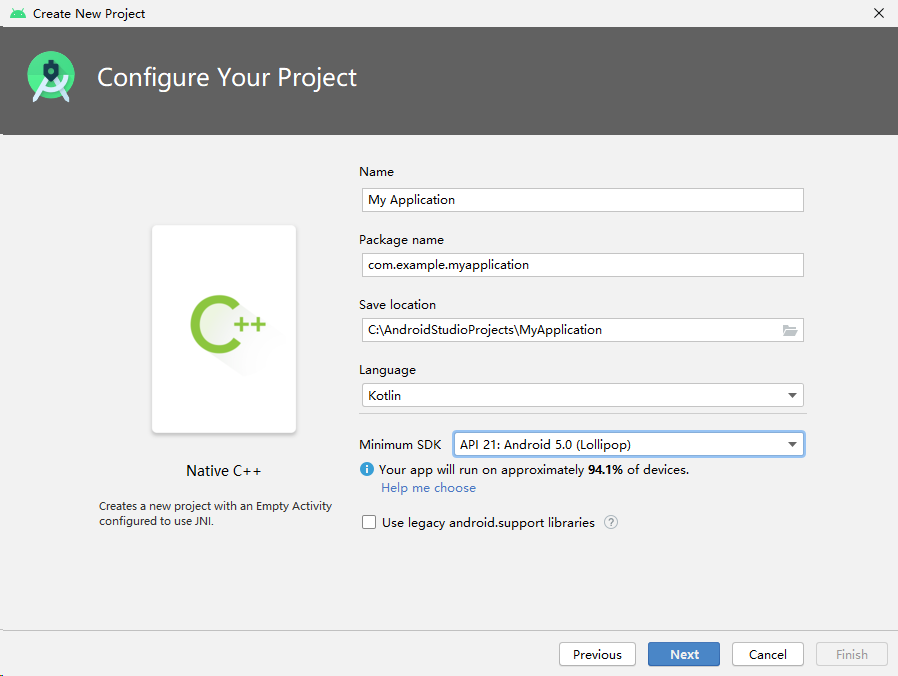
Step 1 - Create an Android Studio project.

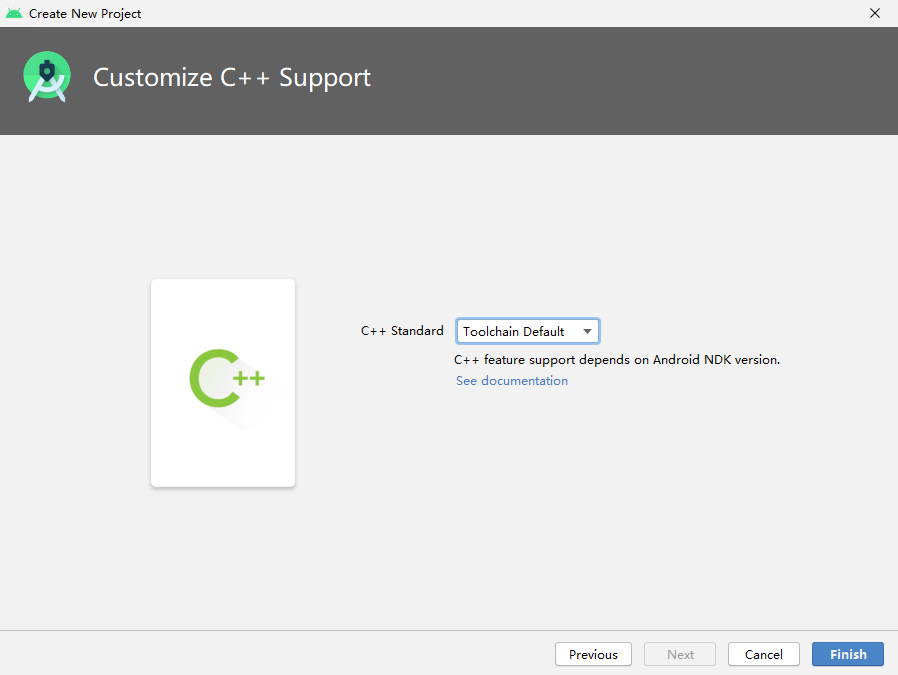
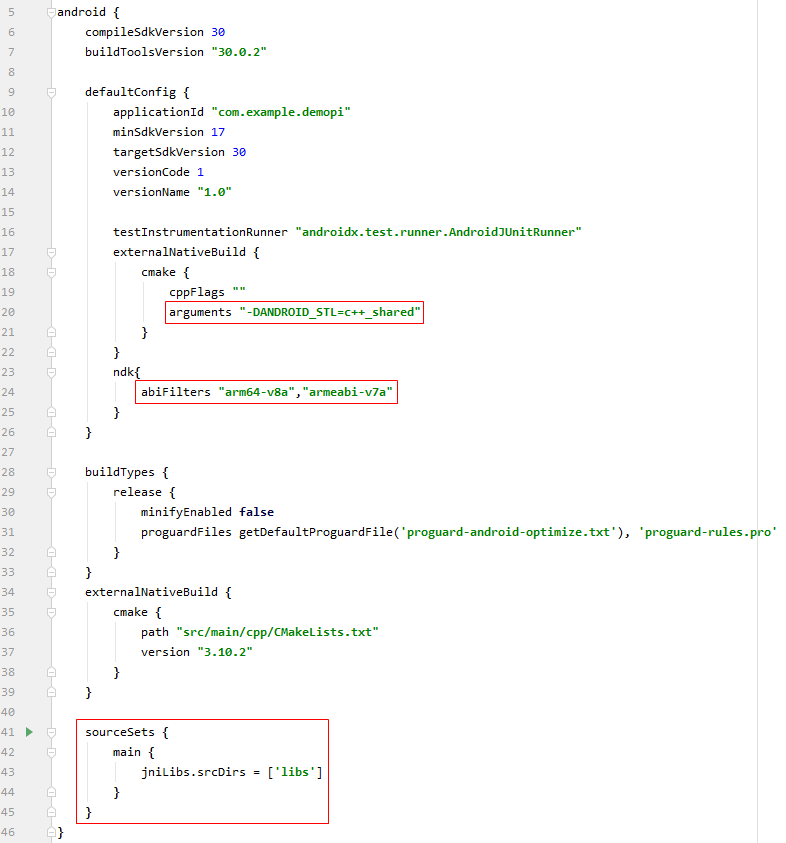
Step 2 - Modify the build.gradle file.
Open the /app/build.gradle file and add the following code lines:
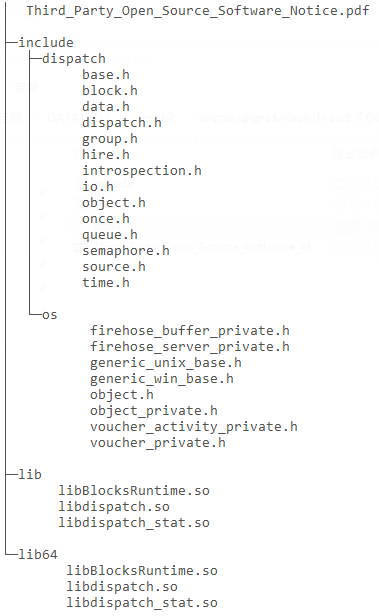
Step 3 - Copy libraries and header files.
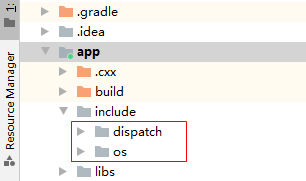
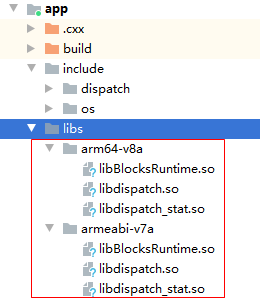
# For more information about using CMake with Android Studio, read the
# documentation: https://d.android.com/studio/projects/add-native-code.html
# Sets the minimum version of CMake required to build the native library.
cmake_minimum_required(VERSION 3.4.1)
# Creates and names a library, sets it as either STATIC
# or SHARED, and provides the relative paths to its source code.
# You can define multiple libraries, and CMake builds them for you.
# Gradle automatically packages shared libraries with your APK.
add_library( # Sets the name of the library.
native-lib
# Sets the library as a shared library.
SHARED
# Provides a relative path to your source file(s).
native-lib.cpp )
# Searches for a specified prebuilt library and stores the path as a
# variable. Because CMake includes system libraries in the search path by
# default, you only need to specify the name of the public NDK library
# you want to add. CMake verifies that the library exists before
# completing its build.
target_include_directories(
native-lib
PRIVATE
${CMAKE_SOURCE_DIR}/../../../include)
find_library( # Sets the name of the path variable.
log-lib
# Specifies the name of the NDK library that
# you want CMake to locate.
log )
add_library(
dispatch
SHARED
IMPORTED)
set_target_properties(
dispatch
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../../../libs/${ANDROID_ABI}/libdispatch.so)
add_library(
BlocksRuntime
SHARED
IMPORTED)
set_target_properties(
BlocksRuntime
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../../../libs/${ANDROID_ABI}/libBlocksRuntime.so)
target_compile_options(native-lib PRIVATE -fblocks)
# Specifies libraries CMake should link to your target library. You
# can link multiple libraries, such as libraries you define in this
# build script, prebuilt third-party libraries, or system libraries.
target_link_libraries( # Specifies the target library.
native-lib
dispatch
BlocksRuntime
# Links the target library to the log library
# included in the NDK.
${log-lib} )
—-End
his section provides instructions for calculating π with the Accelerate Kit APIs. The Gregory-Leibniz infinite series is used to approximate π as follows: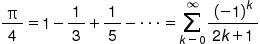
To begin with, break the calculation down into eight tasks (tasks 0–7) so that a part of the infinite series is calculated each task, and the value of 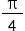 can be obtained by accumulating the result of each task. Then, the value of π is obvious.
can be obtained by accumulating the result of each task. Then, the value of π is obvious.
Set related parameters, including the number of terms n), total number of tasks threads), and initialization of the calculation result pi). Becausepi needs to be updated and modified in a subsequent block, the modifier__block is added.
_block double pi = 0;
int n = 1000000;
int threads = 8;
dispatch_queue_t accumulator = dispatch_queue_create("Compute pi", NULL);
dispatch_apply(threads, DISPATCH_APPLY_AUTO, ^(size_t idx){
//π的分步计算实现
});
int start = idx * (n / threads);
int end = (idx + 1) * (n / threads);
double sum = 0;
for (int k = start; k < end; k++) {
double flag = (k & 1) ? -1.0 : 1.0;
sum += flag / (2 * k + 1);
}
Call dispatch_sync to calculate the sum of each task. Then, obtain 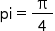 by accumulating the results of the eight tasks.
by accumulating the results of the eight tasks.
dispatch_sync(accumulator, ^{
pi += sum;
});
dispatch_release(accumulator);
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_example_MainActivity_stringFromJNI(
JNIEnv* env,
jobject /* this */)
{
std::stringstream ss;
ss << std::setprecision(20) << calculate_pi();
return env->NewStringUTF(ss.str().c_str());
}
Accelerated computation of π is complete. The following gives the complete code (app/src/main/cpp/native-lib.cpp).
#include <jni.h>
#include <string>
#include <sstream>
#include <iomanip>
#include <android/log.h>
#include <dispatch/dispatch.h>
double calculate_pi(void)
{
__block double pi = 0;
int n = 1000000;
int threads = 8;
dispatch_queue_t accumulator = dispatch_queue_create("Compute pi", NULL);
dispatch_apply(threads, DISPATCH_APPLY_AUTO, ^(size_t idx){
int start = idx * (n / threads);
int end = (idx + 1) * (n / threads);
double sum = 0;
for (int k = start; k < end; k++) {
double flag = (k & 1) ? -1.0 : 1.0;
sum += flag / (2 * k + 1);
}
dispatch_sync(accumulator, ^{
pi += sum;
});
});
dispatch_release(accumulator);
return pi * 4;
}
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_example_MainActivity_stringFromJNI(
JNIEnv* env,
jobject /* this */)
{
std::stringstream ss;
ss << std::setprecision(20) << calculate_pi();
return env->NewStringUTF(ss.str().c_str());
}
Well done. You have successfully completed this codelab and learned how to:
For more information, please refer to related documents.
Download the demo source code used in this codelab from the following address: